
What is Modular
The Modular Platform is an open and fully-integrated suite of AI libraries and tools that accelerates model serving and scales GenAI deployments. It abstracts away hardware complexity so you can run the most popular open models with industry-leading GPU and CPU performance without any code changes.
For teams that need to scale, Modular's fully managed cloud offers dedicated or serverless endpoints. You can also run Modular's inference stack inside your own cloud infrastructure to meet data residency requirements. For self-hosted solutions, our ready-to-deploy Docker container removes the complexity of deploying your own GenAI endpoint.
Unlike other serving solutions, Modular enables customization across the entire stack. You can customize everything from the serving pipeline and model architecture all the way down to the metal by writing custom ops and GPU kernels in Mojo. Most importantly, Modular is hardware-agnostic and free from vendor lock-in—no CUDA required—so your code runs seamlessly across diverse systems.
It takes only a moment to start an OpenAI-compatible endpoint with a model from Hugging Face:
- CLI endpoint
- Docker endpoint
max serve --model google/gemma-3-27b-itdocker run --gpus=1 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/max_cache:/opt/venv/share/max/.max_cache \
-p 8000:8000 \
modular/max-nvidia-full:latest \
--model-path google/gemma-3-27b-itfrom openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="EMPTY")
completion = client.chat.completions.create(
model="google/gemma-3-27b-it",
messages=[
{
"role": "user",
"content": "Write a one-sentence bedtime story about a unicorn.",
},
],
)
print(completion.choices[0].message.content)Try it now
Capabilities
-
High-performance, portable serving: Serve 500+ AI models from Hugging Face using our OpenAI-compatible REST API with industry-leading performance across GPUs and CPUs.
-
Large-scale, GenAI deployment: Scale massive GenAI inference services across thousands of GPU nodes. Modular intelligently routes workloads across models and hardware types to maximize throughput and minimize latency.
-
Flexible, faster development: Deploy with a single Docker container that's under 1GB across multiple hardware types, compile in seconds rather than hours, and develop faster with a slim toolchain that makes versioning and dependency nightmares disappear.
-
Customize everywhere: Customize at any layer of the stack by writing hardware-agnostic GPU and CPU kernels, porting models into Modular's optimized graph format, or programming hardware directly with Mojo (no hardware-specific libraries).
Components
Modular is a vertically integrated AI infrastructure stack that spans that provides entry points for users at every level.
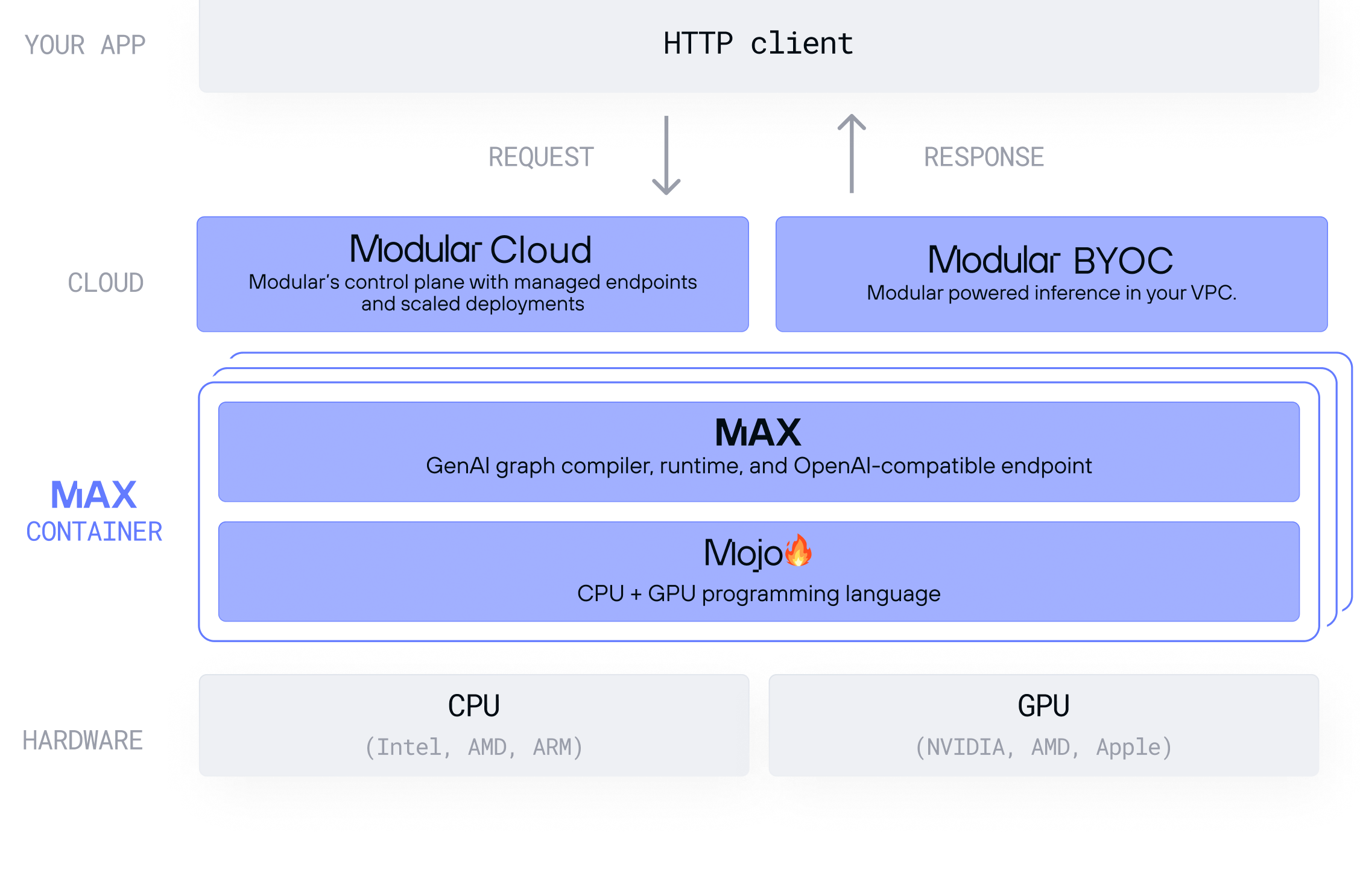
-
☁️ Modular in the cloud: Deploy AI models at scale with Modular's fully managed cloud, or run Modular's inference stack inside your own cloud infrastructure. Choose the deployment model that fits your team's cost, compliance, and control requirements.
-
🧑🏻🚀 MAX: A high-performance AI serving framework that includes advanced model serving optimizations like speculative decoding, and graph compiler optimizations like op-level fusions. It provides an OpenAI-compatible serving endpoint, executes native MAX and PyTorch models across GPUs and CPUs, and can be customized at the model and kernel level.
-
🔥 Mojo: A kernel-focused systems programming language that enables high-performance GPU and CPU programming, blending Pythonic syntax with the performance of C/C++ and the safety of Rust. All the kernels in MAX are written with Mojo and it can be used to extend MAX Models with novel algorithms.
Get started
You can create an OpenAI-compatible REST endpoint using our max CLI or our
Docker container:
-
Start with pip: Install MAX with
pipand run inference with Python or a REST endpoint. -
Start with Docker: Run our Docker container to create a REST endpoint.
In either case, you can select from hundreds of our supported models. You can also load weights from Hugging Face or load your own fine-tuned weights.
For performance optimization, you can port models from PyTorch to MAX using the MAX Graph API. For deeper customization, you can extend MAX Models with custom operations (ops) written in Mojo. Your custom ops are automatically analyzed and fused into the model graph, delivering low-level acceleration without sacrificing developer productivity.
Stay in touch
Once you've explored MAX's features and experimented with self-hosted endpoints, the next step is scaling. Modular's managed cloud solution provides fully-managed dedicated and serverless endpoints. Alternatively, you can use Modular's control plane in your VPC to keep inference inside your own infrastructure for teams with strict data residency requirements. Reach out to talk through your deployment needs.
Talk to an AI Expert
Connect with our product experts to explore how we can help you deploy and serve AI models with high performance, scalability, and cost-efficiency.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!