
Inference routing
Inference routing is the process of directing incoming inference requests to the appropriate worker node in a distributed LLM serving cluster. Rather than simply forwarding requests to the next available worker, an inference router uses configurable routing strategies to intelligently distribute traffic based on workload characteristics, hardware state, and caching conditions.
The inference router receives a prompt from an HTTP server, analyzes the request to extract information relevant to the selected routing strategy, selects a worker based on the routing algorithm and current cluster state, proxies the request to that worker, and streams the response back to the user.
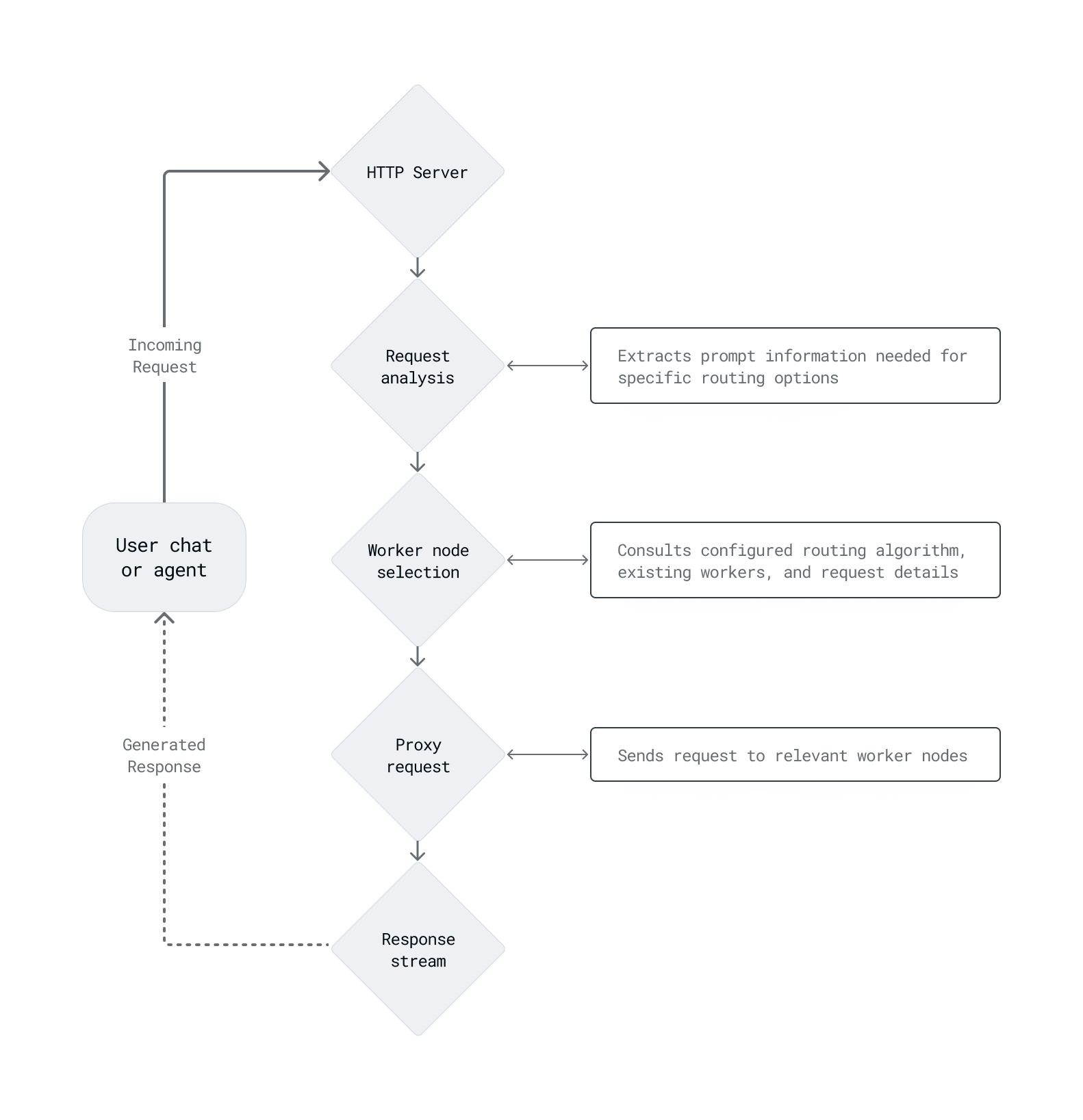
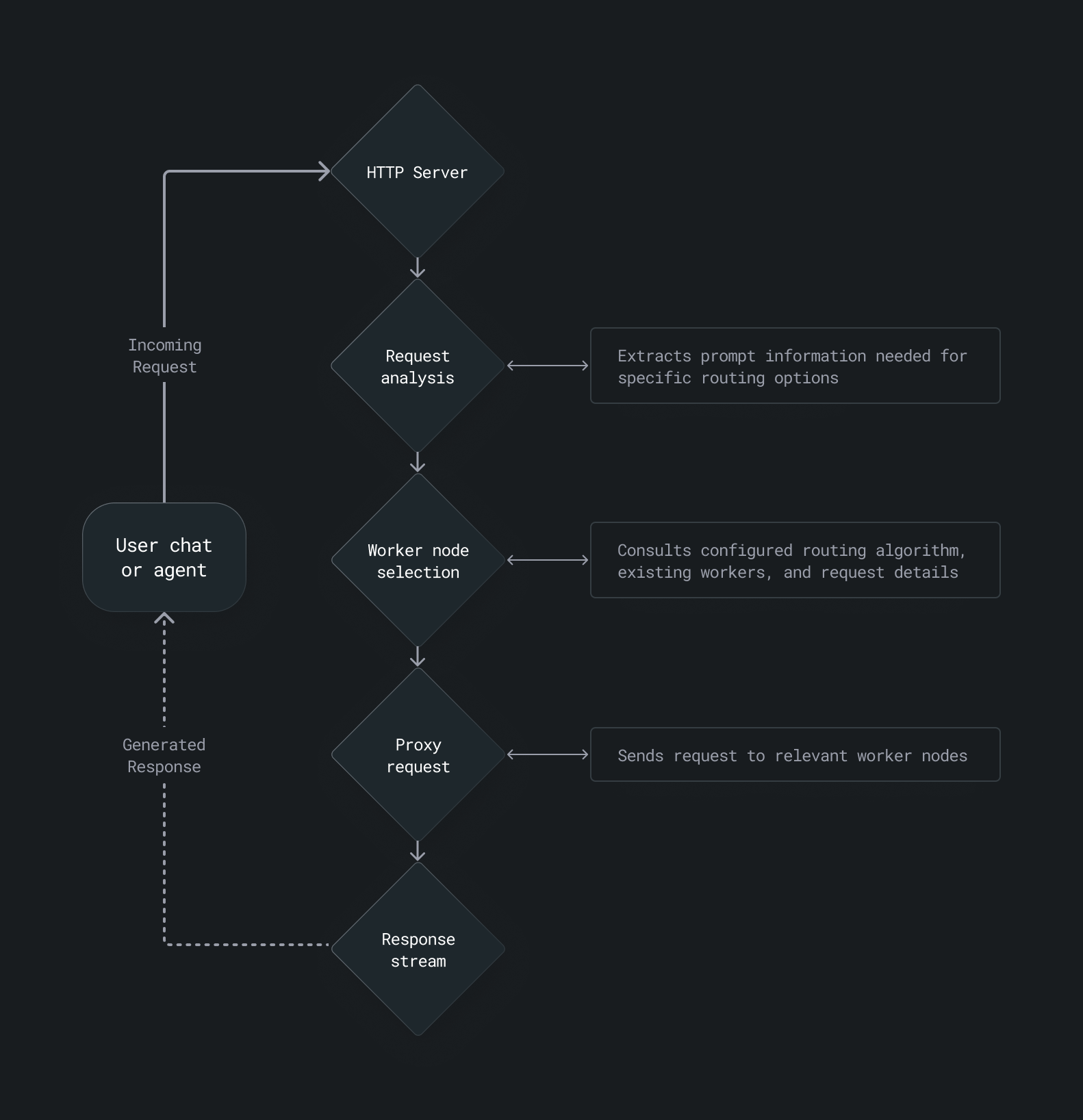
Routing strategies
| Name | Strategy | Use case |
|---|---|---|
| KV cache-aware | Routes based on shared tokens or document chunks in the KV cache | Repeated prompts in chatbots, agents, or RAG-style workflows |
| Least request | Sends requests to the worker with the fewest active requests | Mixed workloads with variable size or latency requirements |
| Prefix-aware | Uses consistent hashing on prompt prefixes to group similar requests | Prompts with shared templates or recurring task descriptions |
| Random | Selects a backend worker at random | Benchmarking and exposing latency variability |
| Round robin | Distributes requests evenly across all workers in sequential order | Stateless, uniform tasks without caching needs |
| Sticky session | Routes requests with the same session ID to the same worker | Session-based chat or apps needing memory and continuity |
KV cache-aware
KV cache-aware routing manages requests based on the contents of the KV cache on each worker. It is most useful for retrieval-augmented generation (RAG) systems where many queries share common document chunks or similar inputs, but not identical prefixes. KV cache-aware routing is especially useful for high-throughput workloads with many repeating or similar tokens across queries.
Least request
Least request routing sends new inference requests to the worker currently handling the fewest active requests. This helps balance load dynamically and reduces the chance of overloading any single worker. It is especially useful for variable-length or unpredictable inference tasks and workloads where you want to minimize tail latency.
Prefix-aware
Prefix-aware routing (also known as consistent hashing) examines the prompt prefix in an incoming request and routes it to the worker handling requests with the same prefix. This maximizes prefix cache reuse: for example, if many users share a common system prompt, that prefix stays cached on a single node. When a worker becomes saturated for a popular prefix, the router automatically distributes the load by spilling over to additional workers, maintaining partial cache locality while balancing traffic.
Prefix-aware routing is especially useful when many users send queries that start with the same instructions or template, or in multi-turn conversations where session stickiness isn't enabled.
Random
Random routing selects a backend worker at random from the pool of available endpoints for each incoming request. It is most useful for benchmarking: by eliminating routing bias, it exposes average worker performance under distributed load and helps identify latency variability across nodes.
Round robin
Round robin routing distributes incoming requests evenly across all available workers in sequential order, cycling back to the first worker after reaching the last. It is well-suited for stateless or homogeneous workloads where each request is independent and caching is not a concern.
Sticky session
Sticky session routing sends a user's requests to the same worker node for the duration of their session, identified by a session ID in the HTTP request header. If no session header is present, the router falls back to round robin. This strategy is most useful for chatbots or streaming applications where in-flight session state is maintained on the server and continuity across requests matters.
Relation to KV cache and prefix caching
Several routing strategies, particularly prefix-aware and KV cache-aware routing, are designed to maximize the value of the KV cache. By routing requests with shared prompt prefixes to the same worker, these strategies reduce redundant computation and improve throughput. See prefix caching for more on how caching works at the serving layer.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!