
Disaggregated inference
Disaggregated inference is a serving architecture pattern for large language models (LLMs) in which the two main phases of inference, prefill and decode, are executed on separate hardware resources. You might also see this technique called disaggregated prefill or disaggregated serving. All of these names describe the same core idea: separating the model's inference phases and providing each phase with dedicated resources optimized for its specific computational characteristics.
Prefill and decode phases
LLM inference involves two distinct phases, each with different performance characteristics.
Prefill (also known as context encoding) is the initial phase where the model processes the entire input prompt. The model performs a full forward pass to initialize its (KV cache) and predict the first output token. This phase is compute-intensive, especially for long prompts, because it involves large-scale matrix operations that demand high floating-point throughput. The key performance metric for this phase is Time-to-First-Token (TTFT): the duration from receiving the input prompt to producing the first output token.
Decode (also known as token generation) is the phase where the model generates output tokens one at a time, using the KV cache initialized during prefill. By leveraging this cache, the model avoids reprocessing the full input each time. The decoding phase is less compute-intensive per token but becomes memory-bound, relying heavily on efficient access to cached data. The key performance metric here is Inter-Token Latency (ITL): the time taken to generate each subsequent token after the first.
How disaggregated inference works
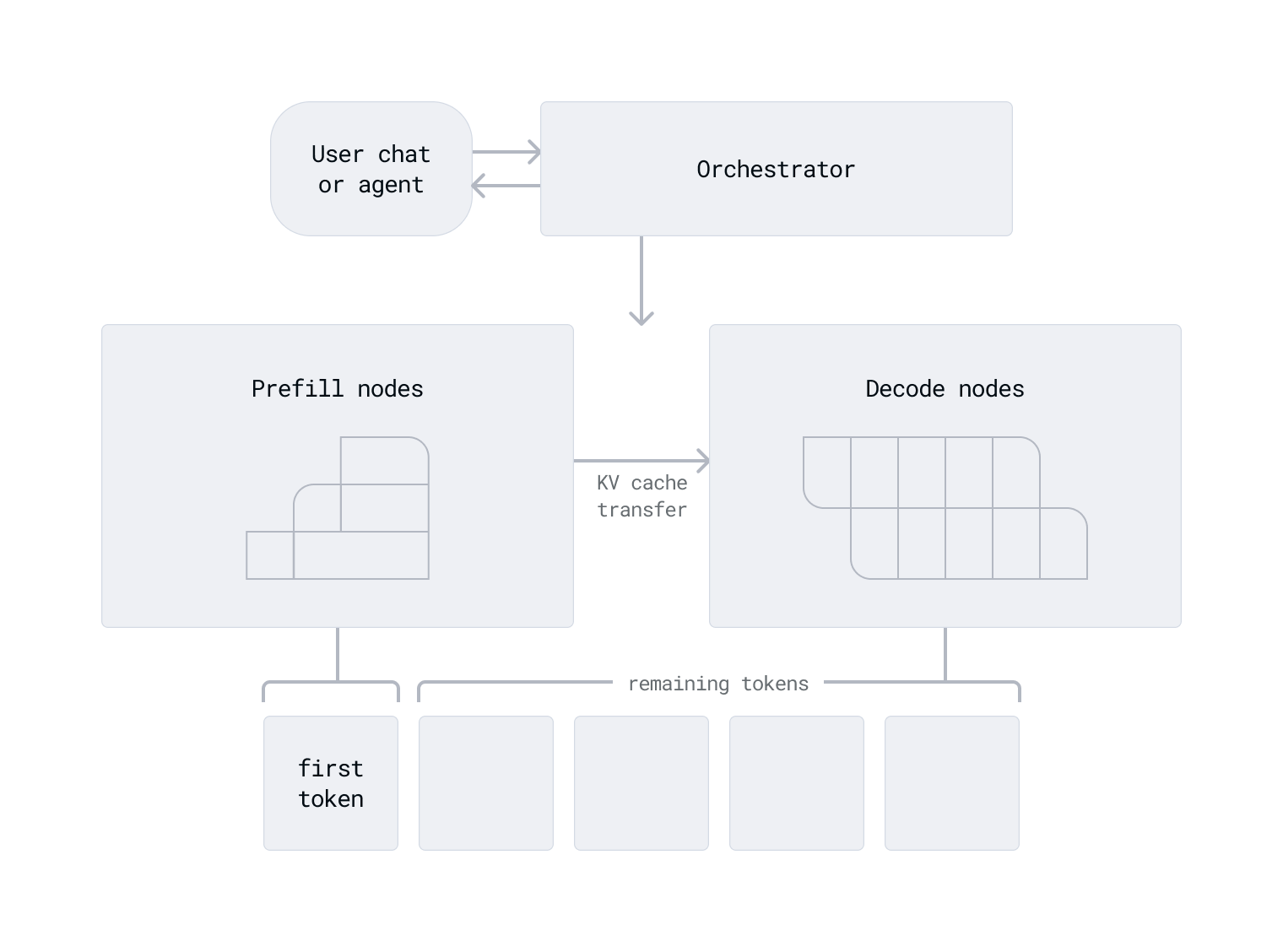
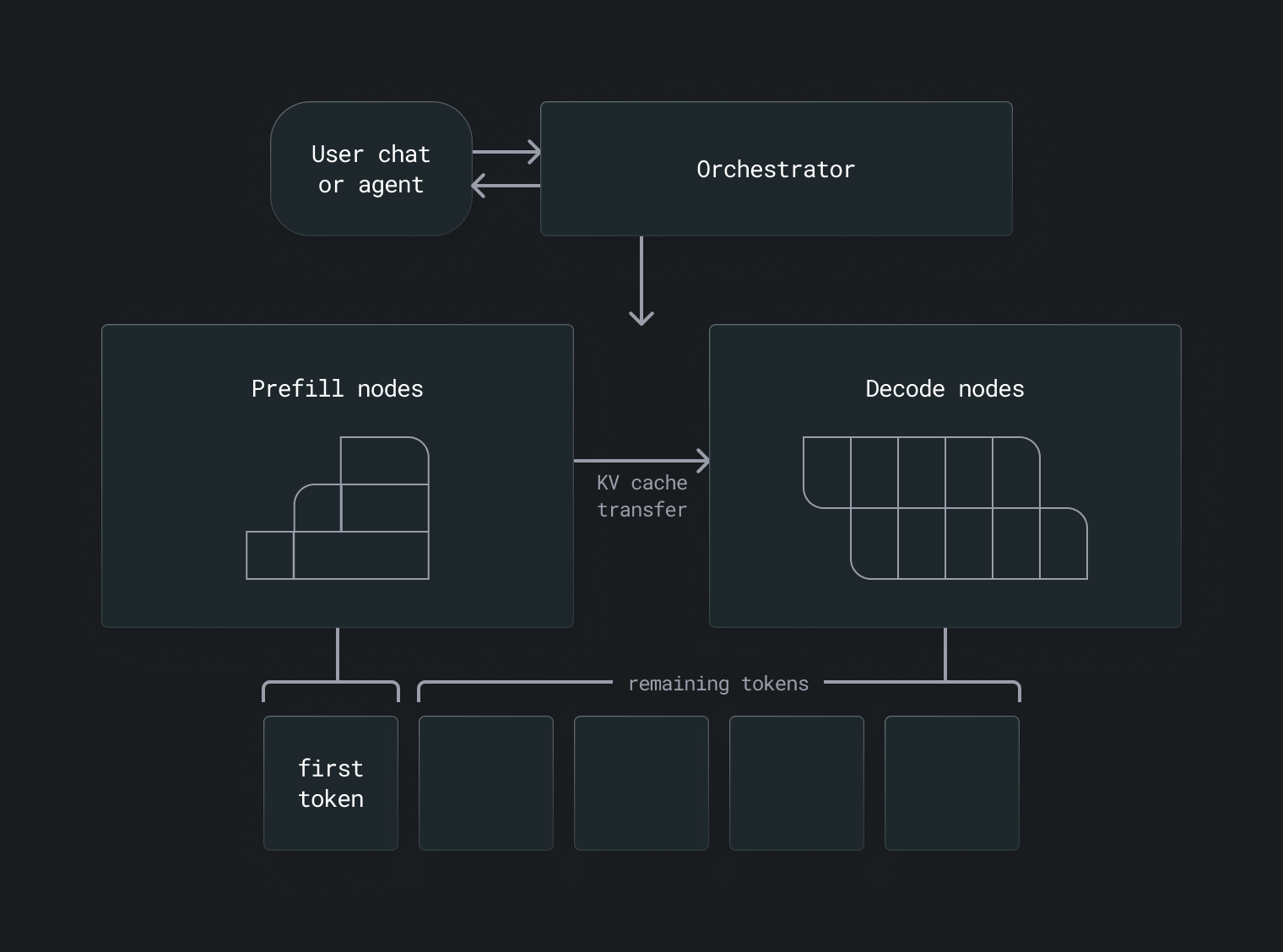
In a disaggregated setup, prefill and decode workloads are routed to different GPUs or GPU nodes. This allows each phase to be optimized independently:
- Prefill nodes are configured with hardware that prioritizes high compute throughput, suited for the intensive matrix operations required to process long input prompts.
- Decode nodes are configured with hardware that prioritizes fast memory access, better suited for the sequential, cache-dependent nature of token generation.
This separation reduces contention between compute-bound and memory-bound tasks, improves GPU utilization, and allows prefill and decode capacity to be scaled independently.
When to use disaggregated inference
Disaggregated inference is most valuable when minimizing latency is a priority. Because the prefill stage is compute-intensive and the decode stage is memory-bound, isolating the two stages and allocating them to different hardware reduces resource contention and helps achieve both faster TTFT and smoother token streaming.
It is especially effective for improving tail latency (such as P95), which measures how long it takes to complete the slowest 95% of requests. Disaggregation also enables more granular parallelism strategies: you can scale prefill and decode nodes independently as demand changes, improving GPU utilization and overall efficiency without over-provisioning capacity just to handle peak workloads.
Disaggregated inference is also well-suited to heterogeneous or resource-constrained environments where you need to match each phase with hardware that fits its specific demands.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!