
Attention
Attention is a mechanism used in AI models such as transformers that enables the model to assign different levels of importance to different tokens (such as words or pixels) in an input sequence. Unlike traditional architectures that treat all input data equally, attention allows the model to capture relationships between tokens that may be far apart in a sequence. This enables large language models (LLMs) to generate coherent, contextually relevant output.
Attention was introduced and refined in the papers Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014) and Effective Approaches to Attention-based Neural Machine Translation (Luong et al., 2015).
How attention works
Attention operates on three vectors: a query (Q), a key (K), and a value (V). The query comes from the token (or sequence) that is looking for information, while the keys and values come from the tokens being looked at. These two sources can be different: for example, in machine translation, a decoder token might query the keys and values of an encoder's output to decide which input words are most relevant. This is sometimes called cross-attention.
Regardless of where the queries, keys, and values originate, the attention operation follows the same steps: it compares each query against every key to produce a matrix of raw attention scores, normalizes the scores (via softmax) into a probability distribution, and uses those probabilities to compute a weighted combination of the value vectors. The result is a new embedding for each query token that encodes the information it gathered from the tokens it attended to.
Self-attention
The most well-known form of attention is self-attention, used in transformer models. In self-attention, the queries, keys, and values all come from the same sequence, which means every token attends to every other token in its own input. This allows the model to build a rich understanding of context by evaluating how each token relates to all others, regardless of their distance in the sequence.
Because self-attention recomputes scores for every token in the sequence, doing so from scratch at each generation step would be expensive. To avoid this, the model saves the calculated keys and values into the KV cache so they can be reused during the next autoregression cycle.
Scaled dot-product attention
The diagram below shows scaled dot-product attention, which is the standard implementation of the attention operation used in transformer models:
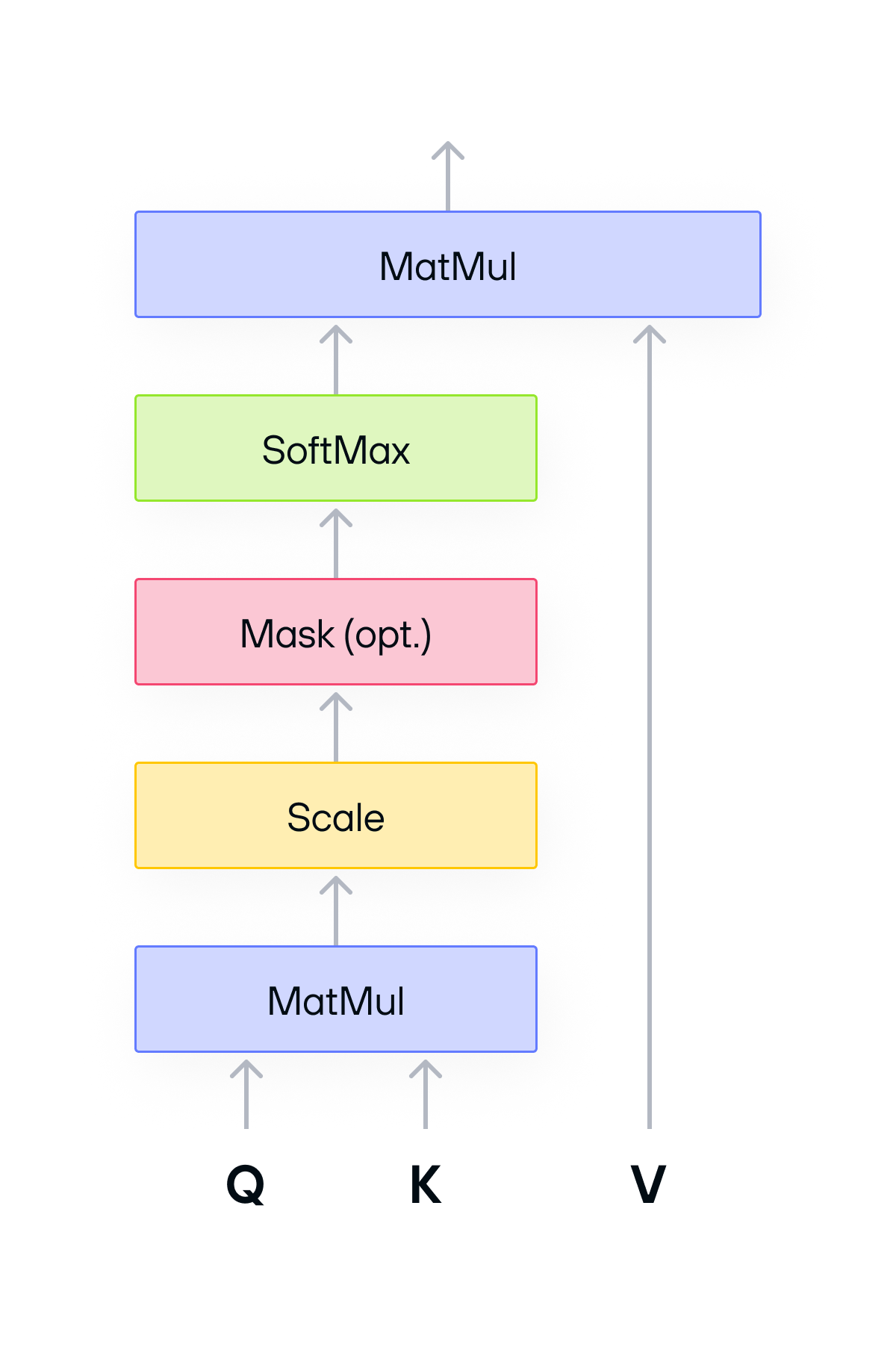
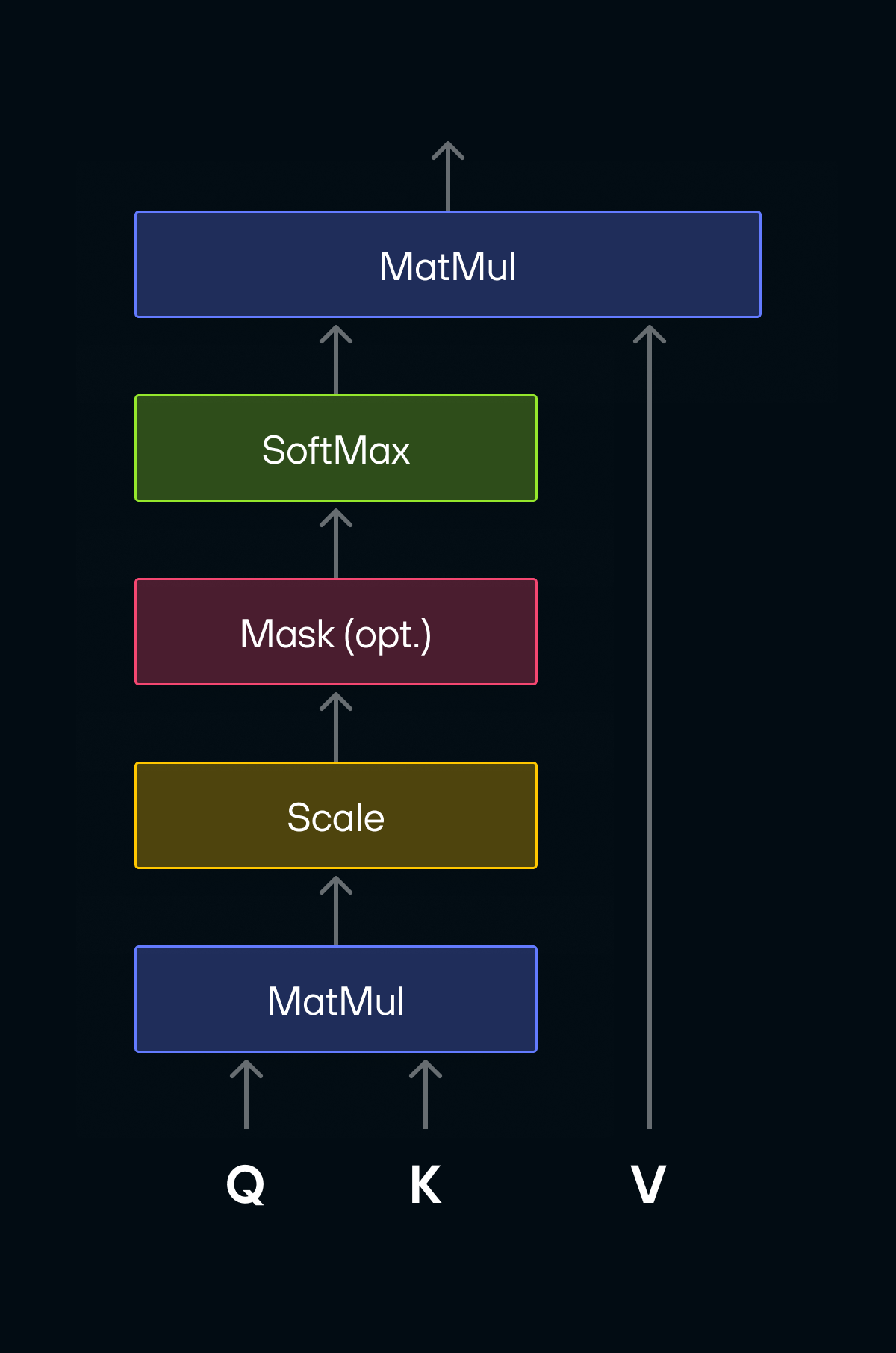
The Q, K, and V matrices each have shape [batchSize, numHeads, S, d], where:
-
Sis the sequence length (which can be as large asO(10^3) - O(10^4)) -
dis the size per attention head in multi-head attention (usually a power of 2 like 64 or 128, and smaller thanS).
These matrices go through the following operations:
-
Q x Transpose(K): Batched matrix multiplication (bmm) that produces a matrix of raw attention scores, one for every pair of tokens. -
softmax: Conversion of the raw scores into a probability distribution so they sum to 1 for each token. -
softmax(Q x K^t) x V: Anotherbmmthat uses the normalized scores to blend every token's value vector into a single output embedding per token.
A limitation of this implementation is that it materializes an intermediate
matrix of shape [batchSize, numHeads, S, S], introducing O(S^2) memory
allocation and traffic.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!